 WebTorrent
WebTorrent
# 用种子(BitTorrent)来渲染前端页面是一种什么体验?
# 前言
聊到种子,可能大家也算是耳熟能详了,可能在我们生活中的一些场景下,它还是很有话语权的。从下载速度层面上来看,种子的能够借助一种“共享”机制来极大的提高资源的下载效率。那既然如此,是不是可以利用这种优势来提高我们网页的加载速度呢?在实现需求之前,我们也需要了解下整个种子的分发方案和基本原理。
# 前置知识
# 了解 Torrent & BitTorrent
在了解 torrent 传输之前,我们可以稍微了解下对等协议(p2p)通信模式。这种模式就类似于会将你的资源进行分布化,你的资源可能存在不同的地方,不同的设备上,以一种分散的形式在其他的设备中,每一个对等方都能给其他对等方提供服务。
# BitTorrent
BitTorrent(中文全称比特流,简称 BT)是一个网络文件传输协议,是能够实现点对点文件分享的技术。在大多数人感觉中与 P2P 成了对等的一组概念,而它也将 P2P 技术发展到了近乎完美的地步。BT有多个发送点,当你在下载时,同时也在上传,也就是这种机制能够建立一个十分有效的分享机制,提高资源的利用率。
所以说,你的种子使用的人越多,那么下载它的速度就会更快
类似于下面这种机制。
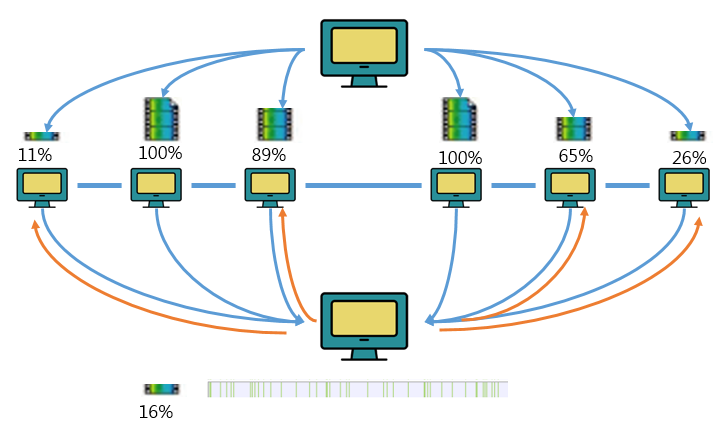
每个用户既是资源的使用方,也是资源的提供方,合作创造双赢的局面。
# Torrent
一般来说,如果我们需要分发我们的种子,我们一般会将一个文件或者文件夹生成一个 .torrent 种子文件。一般来说种子文件中包含了关于目标文件的一些标识数据,它会按照 2k 的整数次方,来进行分片(虚拟分片),然后对每个快生成相对应的 hash 值用来验证块的完整性和唯一性,然后将每个块的 hash 和索引写入到 torrent 文件中。
我们可以大致看下一个 Torrent 的文件结构
这里是随便找了个文件做了个种子
{
"name": "gulpfile.js",
"announce": [
"udp://tracker.leechers-paradise.org:6969",
"udp://tracker.coppersurfer.tk:6969",
"udp://tracker.opentrackr.org:1337",
"udp://explodie.org:6969",
"udp://tracker.empire-js.us:1337",
"wss://tracker.btorrent.xyz",
"wss://tracker.openwebtorrent.com"
],
"infoHash": "0620db0051864b7cda0fd61df5779a5da6531aa6",
"private": false,
"created": "2021-12-20T15:39:17.000Z",
"createdBy": "WebTorrent <https://webtorrent.io>",
"urlList": [],
"files": [
{
"path": "gulpfile.js",
"name": "gulpfile.js",
"length": 1359,
"offset": 0
}
],
"length": 1359,
"pieceLength": 16384,
"lastPieceLength": 1359,
"pieces": [
"bbaf8a989233c80eba320df04c414e7399eb8781"
]
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
这里可以大致介绍下几个字段的用途
- name 表示的种子的名字
- announce 表示的 tracker 的服务地址
- infoHash 表示的这个种子的唯一标识
- files 标识的种子包含的文件列表
- pieces 就是种子的分片了
然后我们可以了解下这个 tracker 是用来做什么的?
其实从名字上来看,它的含义是追踪器,故名思意,就是用来追踪保存种子一些信息的东西。因为如果你做好了种子,想要别人能够拿到下载所需要的信息等等一般就需要一个中心化的 tracker 来记录你的种子信息,然后它会告知使用方种子提供方的信息,用来进行下载。
一般来说我们带着种子的唯一标识去请求这个 tracker 时,它会告知我们现在有多少人在下这个种子,可用的 ip 有哪些,这样我们就可以在各个端点间复用这些下载好的资源,比如某个节点拥有你的目标数据其中的一个块,那么你就直接可以从他这里下载到这个块,同样的如果你有他所需要的块,他也可以从你这进行下载。
# WebRTC
从 Web 端种子的传输方式来看,它本质上还是基于 P2P 连接的方式来建立一条数据传输的通道,通道建立完成之后才能进行相对应的数据传输交互。
说到 P2P 连接,其实我们也会很容易想到另一个与我们息息相关的技术,那就是 WebRTC,它底层也是依靠了 P2P 连接来进行数据传输的,我们可以通过这项技术来简单了解下 P2P 连接的魅力所在。
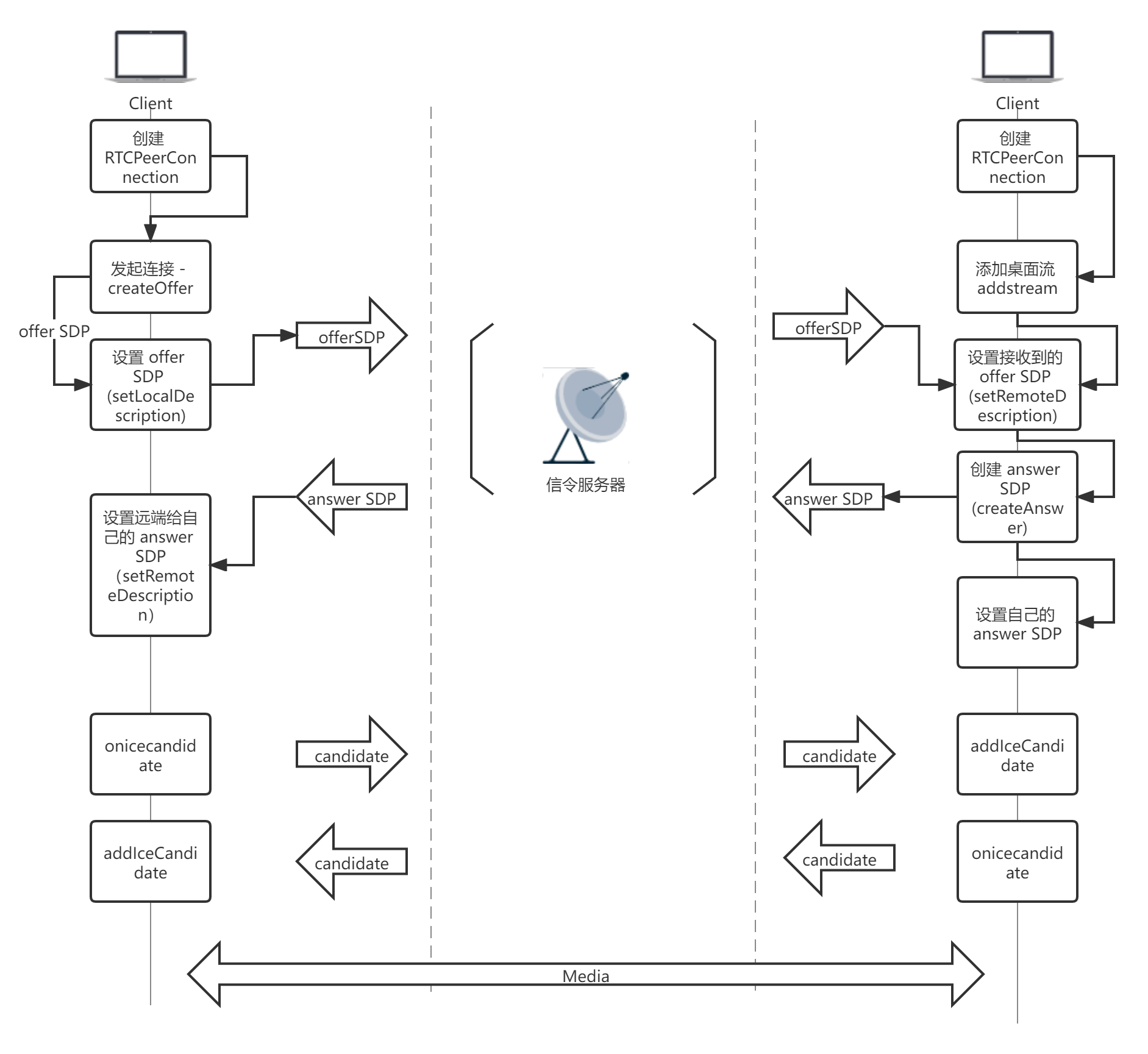
就建立 WebRTC 连接而言,一般来说我们大致需要经历以下这几个步骤:
- 创建 RTC 连接对象
- 发起端创建 offer (SDP 描述信息)
【SDP描述信息】内容:有哪些音视频数据,音视频数据的格式分别是什么,传输地址是什么等;
- 发起端 setLocalDescription(值为上面创建的 offer)
- 将创建好的 offer 数据通过信令服务器来传输给目标端
- 目标端同样自己创建一个 RTC 连接对象
- 如果说需要传输视频流的话就需要 addstream,将流添加到连接通道中
- 目标端收到 offer 后设置 remoteDescription
- 然后创建答复 offer
- 目标端设置自己的 localDescription
- 向发起端发送 answer offer
- 发起端收到 answer offer 之后设置自己的 remoteDescription
# 媒体协议
在 P2P 通信中,同样要关注的还有协议,就像我们使用 http、https、ws 等等,我们都需要协商一套连接双方都支持的编码解码方式进行通信。
WebRTC默认使用V8编解码器,如果要连接的对方不支持V8解码,如果没有媒体协商过程。那么即使连接成功,把视频数据发给对方,对方也无法播放。
比如:Peer-A端可支持VP8、H264多种编码格式,而Peer-B端支持VP9、H264,要保证二端都正确的编解码,最简单的办法就是取它们的交集H264
那在 WebRTC 中,会通过 Session Description Protocol (SDP) 协议来描述相关编解码的信息,在整个 WebRTC 中,参与连接的双方都是需要先交换 SDP 信息,这样双方才能知晓对方需要和支持的信息,这也被称为“媒体协商”。
# NAT
在连接双方交换完媒体协议之后就需要开始了解双方的通信能力了,需要找到一条能够相互通讯链路。那提到这里,我们就要面临一个国内的现状,那就是由于 IPV4 地址空间在国内十分稀少,已经耗尽,没有地址,我们又该如何进行网络冲浪呢?
IPv4 使用 32 位(4 字节)地址,因此地址空间中只有 4,294,967,296(232)个地址。不过,一些地址是为特殊用途所保留的,如专用网络(约 1800 万个地址)和多播地址(约 2.7 亿个地址),这减少了可在互联网上路由的地址数量。随着地址不断被分配给最终用户,IPv4 地址枯竭问题也在随之产生。基于分类网络、无类别域间路由和网络地址转换的地址结构重构显著地减少了地址枯竭的速度。但在 2011 年 2 月 3 日,在最后 5 个地址块被分配给 5 个区域互联网注册管理机构之后,IANA 的主要地址池已经用尽。
在这样的背景下,我们的 NAT 技术开始走上历史舞台。
NAT 名字很准确,网络地址转换,就是替换IP报文头部的地址信息。NAT 通常部署在一个组织的网络出口位置,通过将内部网络 IP 地址替换为出口的 IP 地址提供公网可达性和上层协议的连接能力。不仅如此,NAT 的种类也有多种:
- 一对一的 NAT
- 一对多的 NAT
- 按照NAT端口映射方式分类
- 全锥形NAT
- 限制锥形NAT
- 端口限制锥形NAT
- 对称型NAT
具体的 NAT 细节本文也就不过多赘述,可自行查阅资料。
# NAT 穿透 & STUN
实现 NAT 穿透的方案也有很多,这里也只是提出了其中的一种。
所谓探针技术,是通过在所有参与通信的实体上安装探测插件,以检测网络中是否存在 NAT 网关,并对不同 NAT 模型实施不同穿越方法的一种技术。
STUN 服务器被部署在公网上,用于接收来自通信实体的探测请求,服务器会记录收到请求的报文地址和端口,并填写到回送的响应报文中。客户端根据接收到的响应消息中记录的地址和端口与本地选择的地址和端口进行比较,就能识别出是否存在 NAT 网关。如果存在NAT网关,客户端会使用之前的地址和端口向服务器的另外一个 IP 发起请求,重复前面的探测。然后再比较两次响应返回的结果判断出 NAT 工作的模式。
它主要做的事情就是告诉你,你的公网 IP + 端口是什么,这样你就能将你的信息传达给目标连接方来进行连接了。
其实这块涉及的东西还是挺多的,感兴趣可以看看这个:P2P中的NAT穿越(打洞)方案详解
# MediaStream
一般对于流的传输,我们可以通过浏览器给我们封装好的 API 十分方便的拿到视频流信息与音频流信息,然后通过 addTrack 的方式将音频轨、视频轨、桌面轨之类的数据添加到需要传输的流中去。
不仅如此,浏览器层面还会为我们的音频流做一些优化,如回声消除、降噪、增益等等。
# RTCDataChannel
除了传输一些音视频的流数据之外,我们还可以传输自己自定义的数据,如文本文件、二进制数据等等。
基于这项能力,其实我们也可以做很多其他的事,比如我们可以利用 P2P 通道来发送一些指令数据,实现一个远程控制对方网站(电脑,使用 Electron 方案)能力。
# WebRTC 相关简易 Demo
对应项目地址:demo 项目
示例样式
这里由于笔者台式无摄像头所以是灰色的,不过我们可以看到浏览器 Tab 上的视频状态,左边作为呼叫方,将自己的视频流传输给对方,这里通过信令服务器来获取每个连接的唯一标识来进行数据交换的,还比较粗糙。
这里我们可以从控制台打印来看,他们之间的信息交换与上述图例体现的一致,都是 SDP 和 Candidate 数据的交互,以及流信息的传输。
这里可以稍微提下浏览器获取视频流和音频流的方式:
const mediaStream = await navigator.mediaDevices
.enumerateDevices()
.then(devices => {
const cam = devices.find(function (device) {
return device.kind === 'videoinput'
})
const mic = devices.find(function (device) {
return device.kind === 'audioinput'
})
const constraints = { video: cam && true, audio: mic }
return navigator.mediaDevices.getUserMedia(constraints)
})
mediaStream.getTracks().forEach(track => peer.addTrack(track, mediaStream))
2
3
4
5
6
7
8
9
10
11
12
13
在添加音频或视频流时,我们要判断一下当前设备是否支持音频轨/视频轨。
# Webtorrent
在了解完种子和 P2P 的基本概念之后,我们可以进一步来考虑,如何以 BT 种子的形式来分发我们的网页静态资源呢?
对于一般的前端应用来说,我们都会将所有静态资源打到一个输出文件中,然后可以选择直接使用 nginx 托管静态资源进行访问,也就是说只要为浏览器提供拉取该静态资源的种子即可下载到完整数据了。
# 将静态资源打包成种子
这里笔者将随便拿一个项目过来跑测试
这里将以这个目录来进行举例。
# seed 静态资源
如果想要自己的种子资源能被访问到,我们就需要 seed 目标资源文件,不然下载方就找不到可以下载的源了。
这里笔者也是搭了个 seed 的网页:
只需要把需要 seed 的文件夹拖拽上去就可以了,seed 成功后会给出一个 magnetURL 链接用于种子下载。
我们拿到右边的 magnetURL 就可以随心所欲的下载这个资源啦。
# seed 相关逻辑具体实现
// const trackers = ['wss://tracker.btorrent.xyz', 'wss://tracker.openwebtorrent.com']
const trackers = undefined;
const rtcConfig = {
'iceServers': [
{
'urls': ['stun:stun.l.google.com:19305', 'stun:stun1.l.google.com:19305']
}
]
}
const torrentOpts = {
announce: trackers
}
const trackerOpts = {
announce: trackers,
rtcConfig: rtcConfig
}
const client = new WebTorrent({
tracker: trackerOpts
})
export const seedFiles = (files) => {
client.seed(files, torrentOpts, torrent => {
torrent.on('upload', function (bytes) {
console.log('just uploaded: ' + bytes)
console.log('total uploaded: ' + torrent.uploaded);
console.log('upload speed: ' + torrent.uploadSpeed)
})
console.log('client.seed done', {
magnetURI: torrent.magnetURI,
ready: torrent.ready,
paused: torrent.paused,
done: torrent.done,
});
})
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
依赖了 WebTorrent 这个包提供文件 seed 能力,同时我们为了解决 NAT 的问题,一般需要配置一个 stun 服务地址,用于做 NAT 穿透的能力,也就是上文提到过的,这里笔者直接用了 google 的服务。
这里注意下这个 announce 的配置,它是用来指定对应的跟踪器地址的,如果你在实例化 Webtorrent 的时候传了空,那么它就会用她内置的一些 trackers,这里笔者直接用了它内置的,当然你也可以自己本地搭一个 bittorrent-tracker 服务。
# 下载 & 种子渲染
准备好了种子的下载源,那么我们下一步要解决的就是如何进行下载和渲染呢?
下载能力倒是好说, Webtorrent 包提供了配套下载的 API:
const client = new WebTorrent();
const torrentInstance = client.add(magnetURI, {
path: './'
}, renderTorrent);
2
3
4
这个 renderTorrent 就是用来处理下载完的 torrent 信息的。
# 如何使用这里下载完的静态资源进行页面渲染呢?
答案就是借助 PWA 的能力。
我们拿到下载后的静态资源数据之后,首先可以将静态资源中的入口文件(一般是 index.html)中的数据读取出来,然后直接通过 innerHTML 的方式添加到当前页面中,然后页面就会开始解析这个新插入的 DOM 数据,解析到外部资源引用就会发起一个请求,对于请求的拦截,当然可以轻松的想到 PWA 这个大杀器了。
const renderTorrent = async (torrentInfo: WebTorrent.Torrent) => {
logger.info(`Torrent Downloaded! TorrentInfo: ${torrentInfo}`);
const files = torrentInfo.files;
const indexHtmlFile = torrentInfo.files.find(file => {
return file.name === INDEX_HTML_NAME
});
let index = files.length;
if (!indexHtmlFile) {
logger.error(`can't found index.html`)
} else {
logger.log(`入口文件: ${indexHtmlFile?.name}`)
indexHtmlFile?.getBuffer((err, buffer) => {
if (err) {
logger.error(err);
return;
}
logger.log(`index.html: ${buffer.toString()}`)
document.body.innerHTML = buffer.toString()
})
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
这里简化了一下逻辑
整体逻辑也十分简单,就是从文件列表中查询入口文件,然后读取数据插入到页面当中去。
除了需要处理入口文件之外,我们还需要为 PWA 拦截完请求之后读取资源数据做准备,也就是找个地方先存一下这个数据。
笔者这里准备了两种方案,一个是直接使用 blob 来访问,其次就是使用浏览器 storage 能力,比如 indexDB。
看码:
...
const tempCacheObj = {};
while (index-- > 0) {
const file = files[index];
if (file.name === INDEX_HTML_NAME) continue;
logger.info(`current handle file: ${file.name}`);
try {
const fileGlobUrl = await promisifySetTorrentResponse(file);
tempCacheObj[file.path] = fileGlobUrl;
logger.info(`handler ${file.name} is complete`)
} catch (error) {
logger.error(`handle ${file.name} error: ${error}`);
}
}
// 清理缓存
await localforage.clear()
// 存入缓存
await localforage.setItem(localForageStorageKey, tempCacheObj);
...
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
这段逻辑也是 renderTorrent 处理函数里的,通过遍历处理文件列表的方式来处理静态资源文件。
来看下这个 promisifySetTorrentResponse 逻辑:
const promisifySetTorrentResponse = async (file: WebTorrent.TorrentFile) => {
return new Promise((resolve, reject) => {
file.getBlobURL((e, v) => console.log(v))
file.getBlobURL(async (e: Error, blobUrl: string) => {
if (e) {
logger.error(`获取 fileGlobUrl 异常:` + (e?.message ?? `未知异常)`));
reject(e);
return null;
}
logger.info(`Add ${file.path} to cache.`);
resolve(blobUrl);
});
})
}
2
3
4
5
6
7
8
9
10
11
12
13
14
核心逻辑就是拿到该资源文件的 blobUrl,然后返回给上层处理。而在上层,笔者是将所有的资源 blobUrl 存入到了 indexDB 中,这里为了方便直接用了 localforage 这个包来做本地储存的读取和写入。
除了这种方式,也可以用 cache storage 来做缓存:
const cacheDB = await caches.open(CACHE_NAME);
const res = await self.fetch(blobUrl)
cacheDB.put(reqPath, res.clone());
return res.status === 200
2
3
4
这种方式就是用来直接存一下请求的返回值,可以直接给 PWA 拦截后直接使用。
现在数据都准备好了,是不是就该做渲染逻辑了?
# 为页面注册 ServiceWorker
想使用 PWA 的能力怎么能忘了 ServiceWorker 呢?
看一下基本逻辑:
self.addEventListener('install', async event => {
logger.info('installing!')
await self.skipWaiting();
})
self.addEventListener('activate', async event => {
await clearCache(CACHE_NAME);
await self.clients.claim();
logger.info('activated!')
})
self.addEventListener('fetch', async function (event) {
const request = event.request;
const scope = self.registration.scope;
const url = request.url;
const fetchPath = url.slice(scope?.length ?? 0);
console.log('Fetch request for:')
if (!fetchPath) {
event.respondWith(self.fetch('/index.html'));
} else if (fetchPath === 'intercept/status') {
event.respondWith(new Response('', { status: 234, statusText: 'intercepting' }))
} else {
// event.respondWith(dbResHandler(fetchPath, event))
event.respondWith(handleFetch(fetchPath, event))
}
})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
这里 ServiceWorker 的几个阶段的用途相信使用过 PWA 能力的童鞋都不陌生了,install 就是你的 serviceWorker 安装好了之后会触发的事件,然后 activate 阶段就是你的 ServiceWorker 被激活触发的。
第三个就是我们最关键的事件了,也就是拦截请求的阶段 fetch 阶段,在这个阶段我们就可以来做请求拦截的逻辑啦。
笔者这个项目的处理还比较粗糙,后续可能有机会做成通用能力。
这里笔者写了三个 if else 判断,第一个就主要为了返回主文档的数据,也就是用来承载渲染能力的入口文件,而不是我们要渲染的目标静态资源里的。
也就是下面这个页面:
丑是丑了点,不过顶用就行。
这个网页就主要用来输入目标 magnetURL,然后抓取种子数据到当前页面。
然后笔者的第二个 if else 语句主要用来测试 serviceWorker 是否正常拦截了界面请求的:
if (fetchPath === 'intercept/status') {
event.respondWith(new Response('', { status: 234, statusText: 'intercepting' }))
}
2
3
请求测试端:
function verifyRouter (cb) {
var request = new window.XMLHttpRequest()
request.addEventListener('load', function verifyRouterOnLoad () {
if (this.status !== 234 || this.statusText !== 'intercepting') {
cb(new Error('Service Worker not intercepting http requests, perhaps not properly registered?'))
}
cb()
})
request.open('GET', './intercept/status')
request.send()
}
2
3
4
5
6
7
8
9
10
11
笔者会在注册完成 serviceWorker 之后调用这个函数来测试是否拦截成功,发起一个 Ajax 请求。
然后就是这最后一个 else 语句了,这里就主要用来处理加载其他资源的逻辑了,我们来看看这个 handleFetch 函数都做了什么?
async function handleFetch(fetchUrl: string, event): Promise<Response> {
const filepath2BlobUrlObj = await localforage.getItem(localForageStorageKey);
const currentFileBlob: string = filepath2BlobUrlObj[`${staticPrefix}/${fetchUrl}`]
if (!currentFileBlob) {
console.log(event.request)
return fetch(event.request)
}
const res = await fetch(currentFileBlob);
return res;
}
2
3
4
5
6
7
8
9
10
11
逻辑捋一下:
- 从本地缓存拿到从种子中下载到的所有资源的 path 映射 blobUrl 资源
- 调用 fetch 方法来请求这个 blobUrl 地址
- 将 fetch 请求的接口直接响应给浏览器
# 效果
看了这么久代码,还是得看看效果吧:
我们可以观察右边的 console, 当有人请求这个已经被 seed 的种子文件时,它就会将目标连接需要数据传输过去。
然后再看看渲染端:
可以看到我们的页面被完整渲染出来了,右边控制台笔者打印了一些简要的文件数据。
# 总结
总体来说,这种新玩法还是挺有意思的,感觉还是可以继续探索下去,比编写一个 webpack 插件,在我们页面构建完成之后自动打成种子上传,并给出种子链接,这样我们的页面就直接可以被第三方共享使用了,而且无需服务器维护成本。
这套玩法里面蕴含了很多有意思的东西,不仅仅是渲染页面,这种种子玩法还能做多个文件共享传输能力,多个用户在线实时下载,速度也很快。让我们抛弃某盘,拥抱共享😂。