 介绍
介绍
# 简介
一种用于API的查询语言
官网的介绍总是这么精辟,简单而粗暴。(这里还是要吐槽一句,官方文档真的太太太太不友好了)
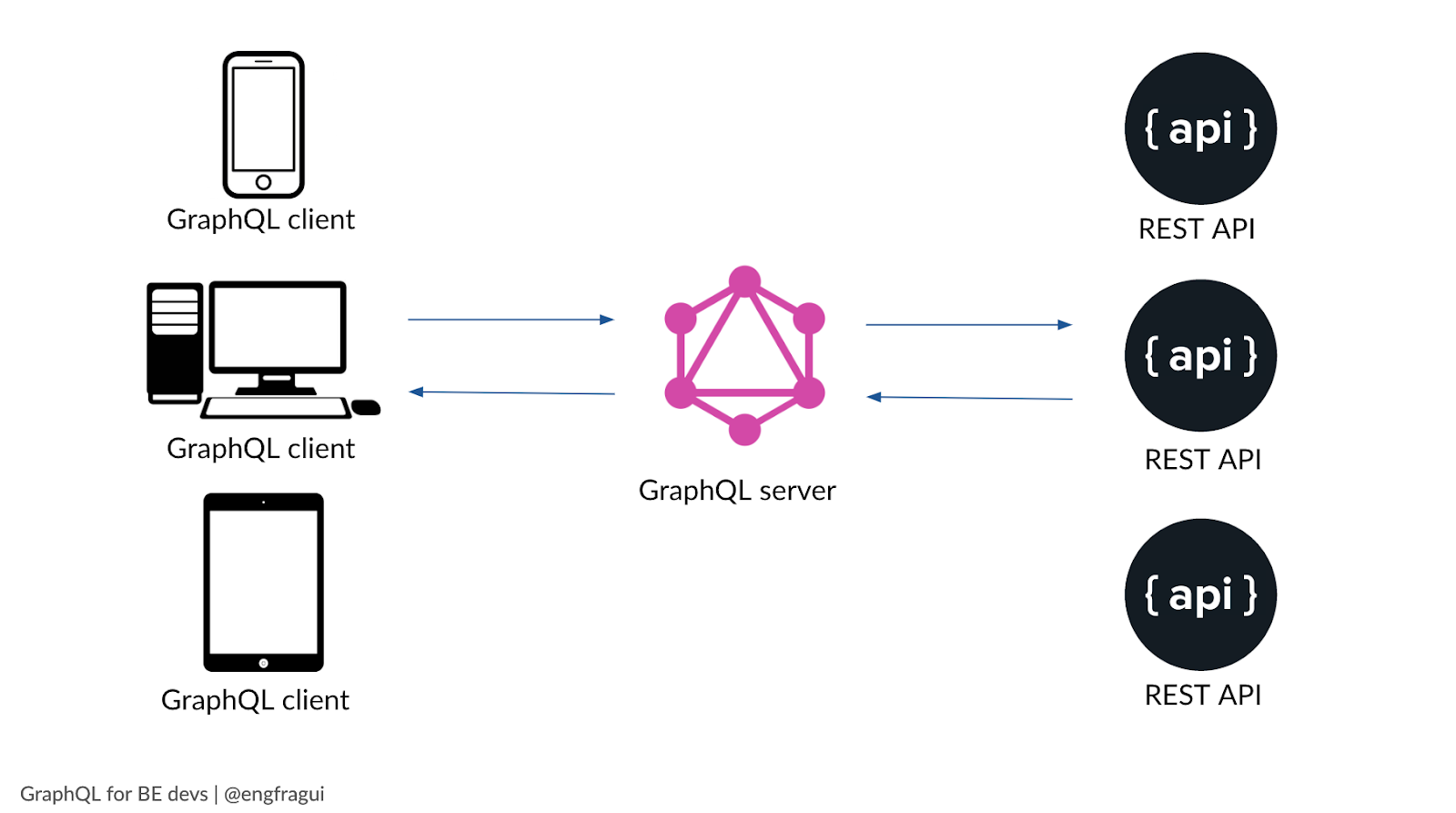
正如这句话所说,GraphQL是一种语言,一种用于API查询的语言。由Facebook开发,用以代替古老的RESTful架构,它允许你用陈述性语句描述你想要的数据,对于每一次请求而言,它总能返回可预测的结果。同时,它支持与多种语言进行一起使用,无论你是JS、Java还是Go...(And so on!),它都能给予稳定的支持,覆盖的语言很多。
Facebook开源了 GraphQL 标准和其 JavaScript 版本的实现。后来主要编程语言也实现了标准。此外,GraphQL 周边的生态不仅仅水平上扩展了不同语言的实现,并且还出现了在GraphQL基础上实现了类库(比如 Apollo 和 Relay)。GraphQL目前被认为是革命性的API工具,因为它可以让客户端在请求中指定希望得到的数据,而不像传统的REST那样只能呆板地在服务端进行预定义。

# 背景
诚然,任何一种技术或者语言的诞生,必然有着它难以割舍的历史背景。
在RESTful架构横行的当下,我们在构建一个前后端项目的同时,几乎总能不假思索的确定服务端API的供给方式。当然,不得不肯定RESTful架构在经过这么多年的考验后依然能屹立不倒,必然拥有着不可或缺的价值所在。有利亦有弊,RESTful也存在或多或少的缺陷。在一个 RESTful 架构下,因为后端开发人员定义在各个 URL的资源上返回的数据,而不是前端开发人员来提出数据需求,使得按需获取数据会非常困难。
从前后端交互角度来说,我们就请求一个接口来说,总会遇到某种场景,前端为了获取或修改到特定的数据需要传递很多个参数,伴随着项目的持续迭代,整个接口请求部分将会变得十分的臃肿且难以维护;不仅如此,如果存在服务端需要兼容多端的情况下,一个接口返回的数据可能会存在许许多多的赘余字段,甚至还可能存在这个页面仅仅只需要寥寥可数的几个字段,请求接口却返回了巨量的数据,从而导致网络带宽的浪费和服务端处理的速度。
对于前端依赖多个接口进行页面渲染的情况来说,几个相关的数据需要发起多个请求来满足需求,这显然是一种不太高效的行为。
从服务端维护的角度来说,对于多个接口,不管是否有存在接口字段重合的情况,我们总是需要编写接口独立的文档用以前端人员的使用,这在很多场景下是十分不友好的。
# 优势
# 渐进式
采用 GraphQL 并不需要将现有技术栈全部一步推翻,正如你计划从一个单体后端应用迁移到一个微服务架构上,这将是很好的一个机会去引入GraphQL API。当你的团队拥有多个微服务时,你的团队可以采用GraphQL聚合Schema的方式来集成一个 GraphQL 网关(gateway)。你可以通过将所有现有的API通过一个API网关不断一步一步汇集到一起,逐步完成到 GraphQL 的迁移。通过这种方式,你可以以较小的代价进行GraphQL架构的接入。
# 版本管理
在传统的RESTful架构中,我们的接口迭代往往伴随着多个API的版本切换(api.domain.com/v1/、api.domain.com/v2/),甚至存在新旧接口共存的情况,在许多情况下前端人员在调用不同接口的时候并没有意识到接口已经处于废弃的阶段,以及新接口的结构的转变,这对于一个项目的长期维护来说必然是存在隐患的。
而对于GraphQL来说,它可以精确到字段级别的废弃,且在前端人员进行使用的时候可以得到良好的提示,你可以灵活的进行各项接口字段的废弃和新增,而调用方能够实时得到同步,这无疑是一种比较友好的交互方式。
# 强类型
GraphQL 是一门强类型的查询语言,因为它是通过 GraphQL Schema Definition Language(SDL)书写的。在这一点上,我们可以对比ts与js的爱恨情仇,强校验对于代码的可维护性来说无疑是意义重大的。GraphQL配合一定编辑器插件不仅能够提供良好的书写提示,还能对代码进行一定的错误检测,能避免一些常见的语法错误。
# 接口健壮性
不再因为后端修改了接口的字段而没有同步前端的情况下导致前端调用出错,然后花费一定时间与后端Battle,这将是十分不友好的行为。为什么说GraphQL就能保证这一点呢,因为该标准下的面向前端的接口都有强类型的校验,完整的类型定义对前端透明,一旦出现前端进行query操作与后端接口定义不符,就能快速感知错误。
# 声明式查询
正如简介所述,GraphQL是一种API查询语言,同时它也是一种声明式的查询语言。客户端可以按照业务需要,通过声明式的方式获取数据。在一次接口调用中,我们可以定义我们想要的字段,服务端将按照用户需要返回特定的字段数据,不多不少,正正好好。在这个过程中,客户端与服务端的关系清晰,客户端只需要关注它需要什么数据,而服务端对自己的数据结构有明确的认知,同时对于每一个字段的数据获取方式有确定的渠道(微服务、数据库、第三方API),各司其职。
# 无数据溢出
它的声明式查询带给了客户端按需获取的能力,每一次的交互只会传输需要用到的字段,不会造成RESTful架构中出现的无关数据大量溢出的情况。
就社区生态而言,由
github、GraphQL的行列。
# 不足
# 复杂查询问题
# 现象
提到这一点,就不得不说起N+1的问题了,那么什么是N+1问题呢?举个栗子:
const allUser = [{id: 1}, {id: 2}, {id: 3}}]
allUser.forEach(item => {
queryScore(item.id);
})
2
3
4
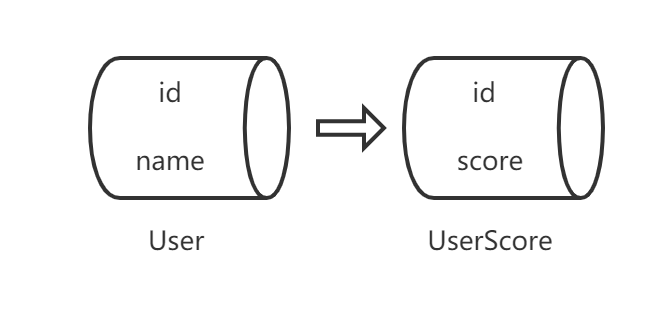
正如上述代码表述,假设数据库设计中用户与用户的成绩分别属于两个表,首先我会需要先拿到包含所有用户id和name的数据,然后通过用户的id去查询用户的成绩,而上述的代码的执行将会导致明明一次查表就能解决的问题,在这里却需要进行"N +1"次操作才能完成,这显然是十分不友好的。
虽然说这不仅仅只有GraphQL才会造成的问题,但是在一定程度上它相较于RESTful更容易出现。这里其实主要会与GraphQL的逐层解析方式所造成的,正如官网所描述的:
GraphQL查询中的每个字段视为返回子类型的父类型函数或方法。事实上,这正是GraphQL的工作原理。每个类型的每个字段都由一个*resolver*函数支持,该函数由GraphQL服务器开发人员提供。当一个字段被执行时,相应的*resolver*被调用以产生下一个值。如果字段产生标量值,例如字符串或数字,则执行完成。如果一个字段产生一个对象,则该查询将继续执行该对象对应字段的解析器,直到生成标量值。
GraphQL查询始终以标量值结束。
# 解决方案
对于关系型数据库而言:
- 针对一对一的关系(比如上面举例中提到的这个
User与UserScore的关系),在从数据库里抓取数据时,就将所需数据join到一张表里。 - 针对多对一或者多对多的关系,你就要用到一个叫做
**DataLoader**的工具库了。其中,Facebook为Node.js社区提供了 DataLoader 的实现。DataLoader的主要功能是batching & caching,可以将多次数据库查询的请求合并为一个,同时已经加载过的数据可以直接从DataLoader的缓存空间中获取到,这样就能处理这种复杂请求的问题了。
# 缓存
一个简单缓存,相比 RESTful,在GraphQL 中实现会变得比较复杂。在 RESTful 中你通过 URL 访问资源,因此你可以在资源级别实现缓存,因为资源使用 URL 作为其标识符。在 GraphQL 中就复杂了,因为即便它操作的是同一个实体,每个查询都各不相同。比如,一个查询中,你可能只会请求一个作者的名字,但是在另外一次查询中你可能也想知道他的电子邮箱地址。这就需要你有一个更加健全的机制中来确保字段级别的缓存,实现起来并不简单。不过,多数基于 GraphQL构建的类库都提供了开箱即用的缓存机制,比如Apollo的缓存能力,它对于前端来说在一定程度上相比于RESTful体验更好。
那么为什么GraphQL不能像传统的RESTful架构一样在服务端加个Header就行了(协商缓存、强缓存),答案是因为RESTful的URL是唯一的,因此可以作为KEY轻松实现缓存,而GraphQL本身只有一个URL,他的查询本质上是通过传Schema参数来实现数据获取或修改的,所以无法按旧有方式来实现缓存能力。
# 解决方案
这里以Apollo Client为例,它为我们提供了缓存策略的可控机制:
# cache-first
缓存优先,顾名思义,在发起请求时先查看是否命中缓存,如果命中则直接返回数据,如果没有则发起一次网络请求获取数据,并更新缓存。
# cache-and-network
该策略所匹配的规则如下:
获取数据时,先检查缓存是否命中,如果命中,同理直接返回,但与缓存优先不同的是,不管缓存是否命中,它都会发起一次网络请求来更新缓存,如果前者没有命中缓存也就是还没有返回数据,那么请求完成之后再返回数据。这种方式的好处在于能够保证缓存数据的实时性。
# network-only
仅仅走网络方式,不走缓存。这种就比较简单了,也就是对于任何请求,它不会检查缓存是否命中,直接发起请求,获取最新数据。
# cache-only
与network-only恰恰相反,这种方式只会检查是否在缓存中,如果获取的数据没在缓存则会抛出错误。如果需要给用户一直显示同个数据而忽略服务端的变化时,或者在离线访问时,这个策略就非常有用了。
# no-cache
同样的,从命名上就能知道该缓存的能力在于所有请求都走网络,不检查缓存,且请求到数据后也不进行数据缓存,如果你的数据只需要最新的,可以采用该方案。
对于策略的设置方式来说,你既可以为整个应用设置fetch policy,也可以单独为某个query设置,至于使用哪种策略,这就需要你根据项目的实际需要来决定了,如果你不设置特定策略,那么Apollo默认会采用cache-first。